新世代の部品表である統合化部品表は製造業に大きなビジネスメリットをもたらすが、その理解のためにはまず第1世代の部品表についての知識が不可欠だ。事実、多くの企業がいまだにこれを運用し続けているのだ。
前回「製造業のバイブル『部品表(BOM)』の復権」では、部品表とその発展形である統合化部品表の概略について述べた。まずは簡単に、その内容をおさらいしておこう。
メインフレーム上で動作するMRP(資材所要量計画)システムのインフラとして誕生した「第1世代」の部品表は、統合化部品表の登場で一気に第2世代から第5世代まで発達することになった。各世代の要点は以下の通りだ。
今回は、まず第1世代の部品表について少し詳しく説明したい。統合化部品表は製造業に多くのメリットをもたらす画期的なインフラだが、その原型となるのはやはり昔ながらのオーソドックスな部品表だ。従って、統合化部品表を理解し、導入するためには、まずはその大本となる第1世代の部品表についての理解が欠かせない。
若干技術的な内容にも踏み込むが、技術者ではない読者にも理解しやすいよう、なるべく簡単に説明したつもりである。部品表を理解する上では必須の知識なので、どうかお付き合い願いたい。
まず、部品表の基本形をごく簡単に説明する。前回でも述べたが、部品表を一言で言うと「製品の組み立てを行うときに必要な部品を、その組み立て順序に応じて階層的に表現した表」である。
例えば、自転車Aという製品を作る例で考えてみよう。下図が、自転車Aがどのような部品で組み立てられているかを示したマスタデータベース、すなわち部品表である(図1)。
ご覧いただければ分かるように、タイヤとフレームからシャーシができて、ハンドルとシャーシから自転車Aが組み立てられるということがデータ構造で表されている。このように部品表は、ある製品のすべての部材・部品と、その組み立て順序を示すデータとなっている。
初期の部品表は、大型メインフレームのデータベースであるCODASYL(Conference on Data Systems Languages:コダシル)型のネットワーク型データベースや、IBMのIMS(Information Management System:アイエムエス)に代表されるような階層型データモデルのデータベースを基に実装された。理論的には無限のデータ階層を持ち得る部品表を、わずか2つのテーブル「品目マスタ」と「構成マスタ」の組み合わせで表現できる画期的なデータモデルだった。
このデータモデルが考案される以前は、部品表のような階層データは階層ごとに個別のテーブルとして実装されたため、大規模な部品表になるとテーブルの数も膨大になる。その結果、パフォーマンスとメンテナンス性に問題が発生することが多かった。ちなみに、これは決して過去の話とは限らず、メインフレームで部品表を運用している企業の中には、現在でもこうした形で部品表が実装されていることが少なくない。

社会人1年目と2年目の意識調査2024 「出世したいと思わない」社会人1年生は44%、2年生は53%
ソニー生命保険が毎年実施している「社会人1年目と2年目の意識調査」の2024年版の結果です。
KARTEに欲しい機能をAIの支援の下で開発 プレイドが「KARTE Craft」の一般提供を開始
サーバレスでKARTEに欲しい機能を、AIの支援の下で開発できる。
ジェンダーレス消費の実態 男性向けメイクアップ需要が伸長
男性の間で美容に関する意識が高まりを見せています。カタリナ マーケティング ジャパン...
![]()
ITmediaはアイティメディア株式会社の登録商標です。
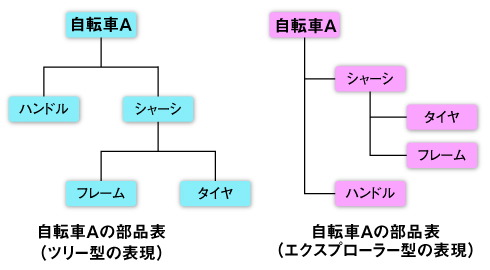 図1 部品表の基本形の例(ツリー型表示とエクスプローラー型表示)
図1 部品表の基本形の例(ツリー型表示とエクスプローラー型表示)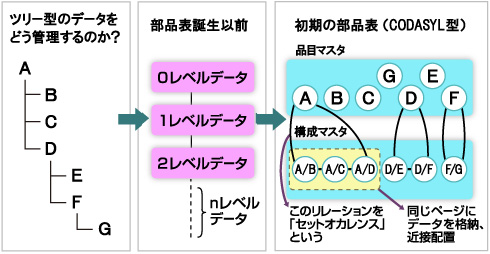 図2 部品表誕生の経緯
図2 部品表誕生の経緯



