DWH市場で存在感を増しつつあるDWHアプライアンスだが、拡張性や汎用性に課題がある。DWHソフトウェアと汎用ハードウェアの組み合わせが、こうした課題の有力な解決策となる。
データ分析をビジネスに積極的に取り入れる、いわゆる「データ経営」の重要性が叫ばれるようになって久しい。近年、「ビッグデータ」というキーワードが取り沙汰されるようになったこともあり、これまでになくビジネスにおけるデータ活用の重要性がクローズアップされている。事実、小売業の世界では、Eコマースとデータ分析技術を効果的に組み合わせたビジネスモデルで躍進を遂げる企業が次々と登場している。
こうした潮流に呼応するように、各ITベンダーもデータ分析やデータウェアハウス(DWH)の製品を次から次へと市場に投入している。中でも近年、高い注目を集めているのが、アプライアンス型のDWH製品だ。ここ数年で、主要な大手ITベンダー各社がせきを切ったように続々とDWHアプライアンス市場への参入を果たしている。
こうした中、ソフトウェアによるDWH製品で革新的な技術を発表してきたのがサイベースだ。世界初のクライアント/サーバ型リレーショナルデータベース(RDB)をリリースしたサイベースが、それとは別にDWH用データベースソフトウェアとしてDWH市場において長年高いシェアを誇ってきた製品が「Sybase IQ」だ。2010年に米Sybaseが独SAPに買収されて以降は、「SAP Sybase IQ」と名前を変えて、SAPブランドの1製品として提供されている。
SAP Sybase IQは、小売業のITにおける「SQLで高速に分析したい」というニーズを受け、最初のカラム型分析プラットフォームとして1996年に産声を上げた。以降、生命保険会社や損害保険会社の契約分析ニーズに多く採用され、Eコマース市場の拡大とともにDWH分野において、もはやデファクトスタンダードといってもいいほどの地位を築き上げている。
そんなサイベースは「ビッグデータ」についてどう捉えているのだろうか。DWH市場に長く関わってきたサイベースの副社長である早川典之氏は、「これまで多く採用されてきたのは、顧客側で『何を分析したいのか』が明確であった市場だ。ビッグデータは、ビッグデータとしてそこにあるわけではない。当社の営業スタッフも顧客に対し、「ビッグデータありますよね」というアプローチをしてしまいがちだが、その場合、顧客からは『うちにはビッグデータはありません』といわれることが多い。しかし、顧客の事業所や本部、支店などに実はデータはある。重要なことは、顧客が何を分析したいのか、分析して何をしたいのか、ということだ。これが明確になって初めて、どのデータを集約するかが決まる。そして、分析の方法論が明確になって初めて、必要なデータを全て一か所に集約すると、おのずとビッグデータになる」と言う。そして、「その分析を実現するインフラとして、機能拡張し続けてきたのがSAP Sybase IQだ」と続ける。
なぜ、ソフトウェアであるSAP Sybase IQが、DWH市場でこれほどまでに高い実績を挙げることができたのだろうか? 早川氏は、「DWHアプライアンスは、限られた小人数が特定の分析をするためのインフラだ。あらかじめ用意された分析テンプレートを使って特定用途の分析処理を高速化するには、確かに向いている。だがベンダーが提供するテンプレートは、競合他社でも利用される可能性がある。こうしたテンプレートを使ったデータ分析が、自社特有の強みや差異化につながるのか疑問だ」と早川氏は指摘する。また、「DWHアプライアンスは、スケーラビリティの効率的な確保が難しい。分析対象データの規模を拡大するたびにハードウェアを買い直していたのでは、あまりにもコストが掛かり過ぎる」と続ける。
その点、SAP Sybase IQは、幅広い種類のアドホック検索を柔軟に処理できる汎用性を持つ。さらに、特定のハードウェアアーキテクチャに依存しないソフトウェア製品ならではの高いスケーラビリティを備えている。
「既存のストレージ環境をそのまま生かしながら導入することができる。システム規模を拡張する際にも、必要最小限のハードウェアリソースを追加するだけで済む」と、早川氏はSAP Sybase IQのメリットを強調する。また、「真に有効なデータ分析を実現するためには、仮説と検証のサイクルを定常的に回していくことが大事だ。SAP Sybase IQの優れたスケーラビリティを生かせば、例えば小規模なテスト環境で分析手法を検証し、効果があると判断された分析手法を順次本番環境で実行する、といったサイクルを頻繁に回すことができる。本番環境に大規模なDWHアプライアンスが1台だけあるような環境では、なかなかこうはいかない」。
汎用性の面でも、さまざまなサードパーティー製品や業界標準技術に対して広くインタフェースを準備している(図)。SAP Sybase IQのアーキテクチャは、大きく分けて「エコシステム」「アプリケーションサービス」「データマネジメント」の3つの階層で構成される。エコシステムは、サードパーティー製のビジネスインテリジェンス(BI)ツールやデータ連係ツール、データベース管理ツールなどとのインタフェースを通じて、広範なシステム連係を可能にする機能群を含むレイヤーである。アプリケーションサービスは、さまざまな開発技術に対応したAPIなどを含むレイヤーだ。
「DWHアプライアンスとは異なり、ユーザーがそれまで運用してきたツールをそのまま利用できるのが、SAP Sybase IQの強みの1つだ。また、デベロッパーに対するサポートを一貫して重視してきたのも、SAP Sybase IQの大きな特徴だ。CやJavaはもちろんのこと、PerlやPHPのAPIまで備えるデータベース製品は、極めて珍しい。それだけ、デベロッパーやシステムインテグレーター(SIer)、パートナーにとっての扱いやすさを重視して開発されている」
このように、ソフトウェアならではの高い拡張性と汎用性を持つSAP Sybase IQだが、ではその処理能力はいかほどなのだろうか? もちろん、ソフトウェアである以上、システム全体のパフォーマンスは、製品が導入されるハードウェアの性能にある程度依存してしまう。それでも、専用ハードウェアで構成されるDWHアプライアンスにも全く引けを取らない処理性能を発揮するという。その秘訣が、先ほど挙げた3階層の中の「データマネジメント」レイヤーにぎっしりと詰まっている。
第一の秘訣は、カラム指向データベースにある。リレーショナルデータベースのように、ロー(行)単位でデータにアクセスするのではなく、カラム(列)単位でアクセスするのが、カラム指向データベースの特徴だ。DWHでよく見られる「特定の列のデータを対象に全件検索する」といったような処理において、インデックスを用いることなく極めて高いパフォーマンスを発揮する。今でこそ、各ベンダーからさまざまなカラム指向データベースが提供されているが、SAP Sybase IQは、いち早くカラム指向データベースを製品化した「先駆け」の製品であり、その安定性や実績には定評がある。
加えて「マルチプレックス」という機能を備えることで、数百人規模のユーザーからアドホックなクエリを同時に受け付けた場合でも、性能劣化を最小限に抑えつつ、クエリを同時平行で処理できる。実は複数クエリ処理における性能劣化は、多くのDWH製品が抱える弱点であり、同時に最も改善が望まれている部分でもある。一昔前までであれば、企業内でデータ分析をするのはごく一握りの専門家だけだった。一方、現在では、現場の従業員が直接データ分析をし、仕事に役立てたいというニーズが高まってきている。その点、SAP Sybase IQであれば、異なる多数のユーザーからのアドホックなクエリ要求を実行待ちキューにため込むことなく、リソースと処理時間を最適に割り振り、効率的に同時処理できる。これはSAP Sybase IQの非常に大きな強みだ。マルチプレックス構成を発展させ、ユーザーグループ単位で各ノード(マシン)をダイナミックに再構成し、特定のノード(群)で特定の業務処理を実行させることもできる。
そして極め付きともいえるSAP Sybase IQの機能が、「PlexQ」と呼ばれる独自技術だ。PlexQは、クエリ処理を複数のノードに割り振り、ディスクI/Oを分散並行処理させることで、高スループットを実現する。いわゆる「MPP(Massively Parallel Processing)」と呼ばれる先進技術だが、SAP Sybase IQが他と異なるのは従来のいわゆるシェアードナッシング型のMPP構成ではなく、シェアードエブリシング型という点だ。幾つかのDWHアプライアンスは、専用ハードウェアでMPPを実現しているが、SAP Sybase IQはソフトウェアの機能(と汎用ハードウェアの組み合わせ)だけで同様の処理を実現する。当然のことながら、DWHアプライアンスと比べて格段に安価に、しかも前述したような高い拡張性と汎用性を維持しつつ、高速データ処理が実現できるのだ。
そんなSAP Sybase IQが、直近のマイナーバージョンアップでさらなる進化を遂げた。2012年4月に日本語版もリリースされた最新バージョン「SAP Sybase IQ 15.4」では、近年注目を集めるビッグデータに対応した機能が大幅に強化された。その最大の目玉ともいうべきなのが、Hadoopのプログラミングモデルである「MapReduce」と、データ分析言語「R」の処理をデータベース内部で実行できる機能だ。
Hadoopは今さら言うまでもなく、ビッグデータの処理基盤として、現在急速に普及が進んでいる技術だ。実は、SAP Sybase IQには、旧来のバージョンからHadoopとの連携機能が備わっており、HDFSのデータとSAP Sybase IQのデータを結合するといったことが可能だった。最新バージョンでは、SAP Sybase IQの内部にMapReduceの処理を取り込み、MapReduceジョブの結果とSAP Sybase IQのデータを結合するといった処理をデータベース内部で実行できるようになったのだ。
このように説明すると、何やら難しいことをやっているように聞こえるかもしれない。だが要は、これまでアプリケーション側で実行していたMapReduceやRの重い処理を、SAP Sybase IQ内部で高速に処理することによって、アプリケーションサーバやクライアント、さらにはネットワークに掛かる負荷を軽減し、システム全体のスループットを大幅に向上できるということなのだ。早川氏によれば、こうしてSAP Sybase IQの分析エンジンとHadoopの間でビッグデータの処理を分担させることで、企業にとってより現実的なビッグデータソリューションが可能になるという。
「これまで、Hadoopでの処理に適さないデータも含め、何でもかんでもHadoopで処理させようとした結果、システム全体の安定性が損なわれるケースが多く見られた。そこで、SAP Sybase IQとHadoopを連係させて、データを両者へ適切に割り振ることで、より効率的かつ安全なビッグデータ処理が可能になる。こうした連係のメリットは、Hadoopについて詳しい技術者なら必ず理解してもらえるはずだ」
またSAP全体では、SAP Sybase IQに加え、インメモリデータベース製品の「SAP HANA」も有している。SAP HANAとSAP Sybase IQの連係も、ユーザーにとってはメリットが大きいと早川氏は言う。
「例えば、基幹システムの共通データ基盤としてSAP HANAを、情報系システムの共通データ基盤としてSAP Sybase IQを使い、かつこの両者を連係させれば、パフォーマンスとスケーラビリティが高い統合データプラットフォームが完成する。SAPでは今後、もともと強かったアプリケーション分野に加えて、こうしたデータプラットフォーム分野にも力を入れ、付加価値の高い統合ソリューションを企業に提供していく」

DWHは、スモールスタートからの拡張性が重要だ。自社の成長に合わせてDWHを柔軟に拡張することができる「SAP Sybase IQ」のハードウェアサイジング指南書で、段階的なビッグデータ分析システムの具体的な拡張イメージをつかんでほしい。
| ホワイトペーパーのダウンロードページへ (TechTargetジャパン) |
Copyright © ITmedia, Inc. All Rights Reserved.
提供:SAPジャパン株式会社、サイベース株式会社
アイティメディア営業企画/制作:TechTarget編集部
![]()
ITmediaはアイティメディア株式会社の登録商標です。
 サイベースの早川典之氏
サイベースの早川典之氏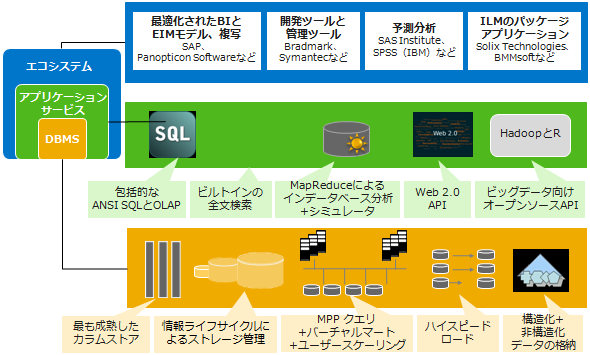 SAP Sybase IQを構成する3つのレイヤー
SAP Sybase IQを構成する3つのレイヤー