ビッグデータ時代の到来を受けて、アナリティクス分野における新しいデータマネジメントのアーキテクチャが注目を集めている。これからのデータウェアハウス(DWH)、次世代の分析基盤に求められる条件とは。
“ビッグデータ”という言葉が広く認知されるようになり、本格的なデータ活用に乗り出す企業が急速に増えている。
一般的に業務システムで必要となるデータは、リレーショナルデータベース(RDB)に整理された状態で格納され、必要に応じて必要な形で素早く取り出せるような仕組みを設けている。
ところが、あらゆるビジネスで高度なデータの集計・分析処理を行うようになり、RDBを構成するハードウェアの負荷が肥大化していった。そこで生まれたのが、集計・分析を専門とするデータウェアハウス(DWH)システムである。特にハードウェア分野では、データを高速処理できる高性能な専用機(アプライアンス)が次々に登場し、高度な分析を迅速に実行できるものとして注目された。
しかしながら、本格的なビッグデータの時代が到来すると、DWH専用機にも制限があることが知られるようになってきた。これまでにないほどの大きなデータを扱うこと、さまざまな種類のデータを分析すること、非構造化データも含まれることなど、本当のビッグデータが持つ特徴は、従来のDWHやRDBでは対応が困難なのだ。
そこで、アナリティクス分野における新しいデータマネジメントのアーキテクチャが注目を集めている。ビッグデータ時代の新しいDWH、次世代の分析基盤に求められる条件を解き明かしていこう。
まず、単純なデータ格納場所としてのデータベースについて考えてみよう。以前からある業務システムの配下として機能するデータベースには、「速さ」「正確さ」「頑丈さ(堅牢性)」といった3つの条件が求められている。
基幹システムの中でも最もミッションクリティカルな勘定系システムを想像していただければ、これらのキーワードの重要性が理解できるだろう。
特に勘定系はデータ量が非常に多く、限られた時間内に集計を終えなければならないシステムであるため、データベースの速さは重要なファクターだ。高速化を実現するため、データのインデックス化やパーティション、マテリアライズドビュー、分散処理などのソフトウェア技術や、さらにインメモリデータベースのような技術が活用されてきた。
また、金銭を取り扱うシステムにおいて、正確さの重要性は言うまでもない。さまざまなユーザーがアクセスする同時実行性、一貫した結果を発する整合性を確保することは、特に勘定系システムにおいては重要だ。
堅牢性についても、もはや疑う必要はないだろう。データのバックアップ&リカバリはもちろん、分散構成やデータレプリケーションといった技術を活用して、システム全体の可用性を高める工夫がなされている。
しかし、日本IBM アナリティクス事業部 ビッグデータ・テクニカル・セールスの一志達也氏は、分析基盤としてのデータベースでは、この条件が変化すると述べる。
現状のデータから将来を見通すような予測分析の分野では、データそのものの正確性はそれほど求められない。例えば、Twitterで“よい”とつぶやかれた回数が1000回でも1001回でも、予測は対して変わらないためだ。また処理の特性上、勘定系システムほどの堅牢性も必要ではない。
分析基盤に必要なことは、「速さ」「予測性(賢さ)」「柔軟性(流動性)」の3つであるという。
「データベースとしての速さは分析においても重要な要素ですが、それ以上に予測性に優れた“賢い”データベースが求められます。さらに流動性あるいは柔軟性、つまりデータの発生源に近いところでリアルタイムに分析できたり、格納場所を意識せずに活用できたり、複数の場所に保存されたデータを透過的に連係したりする能力が必要です」(一志氏)
予測性を向上する技術としては、中核となる予測分析の技術の他、注目されている統計解析向けのプログラム言語「R」への対応、データを移動せずに分析を可能とする「インメモリアナリティクス」技術などが挙げられる。私たちが日常に利用する自然言語の処理機能も、技術的なハードルを下げる点で、統計学などに精通したアナリストやマーケッターにとって大きな助けとなる。
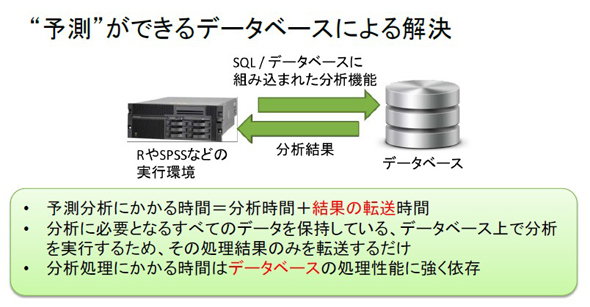
一般的な予測分析の環境では、R言語や「IBM SPSS」などの実行環境へ、SQLによってデータベースから対象となる全てのデータを転送するという作業が必要となる。ここでデータ転送という作業に注目してほしい。
予測分析はできるだけ多くのデータの分析をさまざまな切り口から試行することが望ましい。従って、分析に要する時間はできるだけ短い方がよい。だからこそ、実行環境の性能が高くて速いほどよい。
ところが、予測分析にかかる“総時間”とは、分析の時間にデータ転送の時間を加えたものになる。膨大な量のデータを分析する必要がある場合には、当然のことながら長時間の転送が必要となる。
そこで、予測分析の機能をデータベース側に組み込む「インデータベース・アナリティクス」という手法がある。全てのデータを保持しているデータベース側のシステムで分析を実行し、結果のみを転送すれば、分析に要する総時間を大幅に削減できる。
ただし、この手法にも大きな問題がある。分析処理自体の速さが、データベース側の処理能力に大きく依存するという点だ。従って、業務システムなどをそのまま流用することは非常に難しい。定期的なバッチ処理ならいざしらず、人が不定期に実行する分析処理で負荷が増大するようでは、通常の業務処理に大きく影響してしまう。
では、非常に高性能なハードウェアを用いるだけで、インデータベース・アナリティクスを問題なく実施できるかというと、それだけでは不十分である。
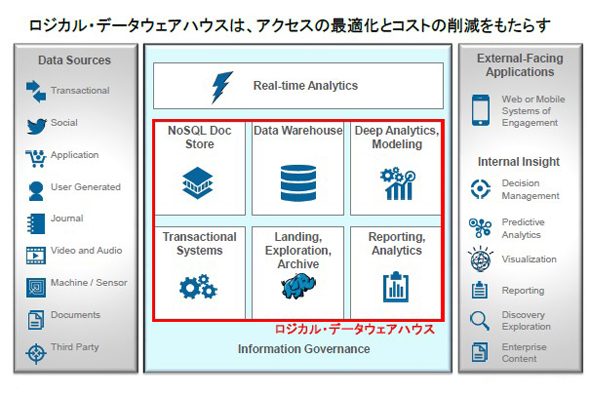
「私たちが分析したいデータは、従来のようなDWH用のデータベースやクラウド上のデータベース、NoSQLのデータストア、最近人気の『Apache Hadoop』など、さまざまな“容れ物”に格納されています。しかし、本当に行いたいのは、これらを横断的に分析することです。例えば、クラウド上のデータと業務システムのデータを相関分析したいというニーズは典型的なものでしょう。それを可能にするのが、ロジカルDWHのアーキテクチャです」(一志氏)
そこでIBMは、データ形式やデータ格納場所にとらわれずに横断的な分析を可能にするアプローチとして、「IBM PureData System for Analytics」や「IBM BigInsights for Apache Hadoop」などのいわゆるクエリエンジンを連携させる、ロジカルDWHソリューションを提供している。データをクエリエンジンに移動するのではなく、クエリを最適なデータソースに振り分けてデータが存在する場所でクエリを実行するという発想だ。
また、データの移動や変換が必要な場合であっても、それを最小限にとどめるソリューションが提供されている。基幹業務系のメインフレーム(「IBM zEnterprise System」)とPureData System for Analyticsとを連係する「IBM DB2 Analytics Accelerator」(IDAA)、Hadoopシステムをあたかもデータベースのように用いることのできるBigInsightsのIBM BigSQL機能、NoSQLデータベース「IBM Cloudant」から、クラウドDWH「IBM dashDB」内のRDBへの自動データ変換機能などだ。データの移動や変換を最小限にし、標準技術であるSQLを使える環境を広げることで、コストを抑えて活用できるデータ範囲を広げるという効果が得られるというわけだ。これが“IBMのロジカルDWH”の柔軟性である。
分析の横断性については、「IBM Fluid Query」というソフトウェアが無償で提供されている。これは、PureData System for AnalyticsとHadoop(IBM BigInsightsの他、Cloudera、HortonWorksに対応。その他も順次対応予定)との相互アクセス性を確保する技術であり、いずれのシステムからでも互いのデータを透過的に分析できるようになる。
場所にとらわれないというのは、すなわちオンプレミス上でもクラウド上でも、パブリックでもプライベートでも、データが格納されている場所を意識せずに、同じ分析機能を利用できるという意味だ。
「クラウドは技術的にもコスト的にも取り付きやすいため、入口としては適しているでしょう。しかし、後からオンプレミスシステムのデータを組み合わせる必要が生じたらどうすればよいのでしょうか。例えば、TwitterのようなSNSのデータと自社で保有している基幹業務データを連携して分析したいというニーズは高いはずです。IBMの分析システムは、同じ基盤、同じ言語、同じ技術で、オンプレミスでもクラウドでもシームレスに横断・連携できることを目指して開発が進められています」(一志氏)
1つ1つの分析技術を見てみれば、強力な競合製品があったり、デファクトに近い技術があったりする。しかしIBMは、ITの総合ベンダーとして、全てを同じ技術基盤に載せることができる点が強みの1つである。そしてもう1つ、重要な力をIBMは持っていると、一志氏は主張する。
「多くの企業は“データを活用するために分析をしよう”と考えがちです。その結果、“分析技術って何?”“Hadoopって何?”と立ち止まってしまうのです。ビジネス上の課題は何かという命題に対して、仮説を立証したり将来を予測したりするためにデータを検証するのがアナリティクスの本質です。IBMでは、そのためのコンサルティングから技術の提供まで、あらゆる面でユーザーをサポートすることができます」(一志氏)
日本企業の分析に対する取り組みは、依然としてプロセス中心で世界的にも決して進んでいるとはいえない。今後は、「洞察(インサイト)中心」の分析へシフトしていくことが必要だ。そのためにも、従来のDWHをロジカルDWHへと“モダナイゼーション”(近代化)していくことが求められる。IBMのロジカル・データウェアハウス・ソリューションと強力なビジネスコンサルティングによって、「IBMは企業のデータ活用を成功に導く」と一志氏は述べている。
ビッグデータ分析基盤を構築する企業が増えている一方、その成果について明確なビジョンが持てないという企業の声もよく聞かれる。投資判断に迷うユーザーにとって、ビッグデータ分析の最適なアプローチ方法を把握することが肝要だ。
Hadoopに使いやすさと自動化を──OSSとエンタープライズ機能の融合
ビッグデータ格納・分析基盤にHadoopの採用を検討する企業が増えているが、その真価を引き出すには高度なスキルと多大な労力が必要だ。ビジネスアナリスト、データサイエンティスト、そしてIT管理者のために「IBM BigInsights for Apache Hadoop」に搭載された新機能の詳細を見ていこう。
提供:日本アイ・ビー・エム株式会社
アイティメディア営業企画/制作:TechTargetジャパン編集部
![]()
ITmediaはアイティメディア株式会社の登録商標です。