Microsoftのビッグデータ投資の成果がいよいよ形に:MicrosoftとGoogleのビッグデータ計画【前編】
MicrosoftとGoogleは、ビッグデータ活用によるビッグマネー獲得を現実に近づけてくれるかもしれない。前編ではMicrosoftが提供するビッグデータ活用ソリューションの詳細を紹介する。
CIOたちは膨大な量のデータセット、いわゆるビッグデータから、有益な情報を引き出だしたいと考えている。しかし、多くの企業にとってビッグデータはビッグマネーを意味する。パブリッククラウドプロバイダーは、そうしたビッグデータの夢を現実に一歩近づけてくれるかもしれない。
TバイトあるいはP(ペタ)バイト単位のビッグデータは、一般的にWebサーバログ、販売記録データ、ソーシャルネットワーク、そしてメッセージングデータなどで構成される(参考:読めば分かる! ビッグデータのためのデータウェアハウス(DWH)とは?)。IBMが実施したEssential CIO調査では、インタビューに応じた3000人のCIOのうち、83%のCIOがビジネス分析関連の投資を最優先事項に挙げている。またGartnerによると、2015年までにビッグデータと大容量情報管理技術を導入した企業は未対応の競合企業に対し、あらゆる財務的指標において20%の差をつけるようになるという(参考:大量データの高速処理化が進むDWH、積極化するユーザー企業の投資意欲)。
しかし、最新の分析手法を必要とするビッグデータストレージとそのコンピューティングリソースの予算化は、今日の経済環境を考えると必ずしも容易ではない。それ故多くのCIOは今、オンデマンドの柔軟性に富んだインフラストラクチャプラットフォームを実現するために、パブリッククラウドコンピューティングプロバイダーに目を向けている。検索エンジン、データセンター投資、そしてクラウドコンピューティングの知識に関して、Microsoftのスティーブ・バルマーCEOはこう話す。「実際のところ、MicrosoftとGoogle以外に、ビッグデータを扱える企業はない」
Microsoftの「LINQ Pack」「LINQ to HPC」「Projekt Daytona」、そして間もなく登場する「Excel DataScope」は、リサーチャーやビジネスアナリストたちが「Windows Azure」のビッグデータ分析にアクセスできるように明示的に設計された。Googleの「Fusion Tables」は、まだクラウドでビッグデータを処理できるようにセットアップされていないが、それでもこのアプリケーションは非常に使いやすく、今後広く普及することが見込まれる。企業は今こそ「未対応の競合他社」を突き放すべく、エクストリームデータ管理に向けて準備すべきときなのだ。
Windows Azure関連記事
- オンプレミスとの連携を意識した「Windows Azure」
- Windows Azureサービスに関してIT管理者が知っておくべきこと
- Windows Azure導入前に確認すべき3つの項目
- Windows Azureへの移行を誘うMicrosoftの巧みな手段
LINQ to HPCはMicrosoftのビッグデータ投資の成果
MicrosoftはWindows Azure Marketplace DataMarketで、ビッグデータシンジケート市場に足を踏み入れた。しかし、クラウドベースのビッグデータ分析に関する同社の投資は、収益性の高いソフトウェアとサービスを目指して始まったばかりだ。例えば2011年6月、MicrosoftのHigh Performance Computing(HPC)チームは、「HPC Pack for Windows HPC Server 2008」クラスタのBeta 2と「LINQ to HPC R2 SP2」をリリースした。
Microsoftの検索エンジンBing(関連記事:Bing、Kinect……血まみれになってITパワーを維持するMicrosoft)は、HPC PackとLINQ to HPCを利用している。これらはMicrosoft Research(MSR)の数年間に及ぶ開発段階において、それぞれDryad、Dryad LINQと呼ばれていたものだ。LINQ to HPCはDistributed Storage Catalog(DSC)で定義されたファイルセットにストアされた非構造化ビッグデータの分析に用いられる。デフォルトでは、複数のコンピュートノードでHPC Server 2008/HPC Pack R2 SP2を実行する個別のマシン上に、3つのDSCファイルレプリカがインストールされる。そしてLINQ to HPCアプリケーションまたはジョブが、DSCファイルセットを処理する。Chappell & Associatesの代表、デビッド・チャペル氏によると、LINQ to HPCのコンポーネントは、オンプレミスのハードウェアを利用する「Windows HPC Serverによるデータ集約型コンピューティング」だという(図1)。
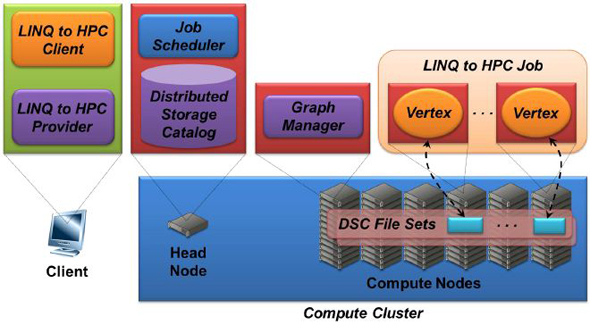
LINQ to HPCクライアントは、LINQクエリを実行する.NET C#またはVBプロジェクトを含み、LINQ to HPCプロバイダーがLINQクエリをヘッドノードのジョブスケジューラに送る。LINQ to HPCは無閉路有向グラフデータモデルを利用する。グラフデータベースは、ドキュメントとしてリレーションを利用するドキュメントデータベースだ。ジョブスケジューラはグラフを操作するグラフマネジャーを作成する。
LINQ to HPCアーキテクチャの利点の1つは、.NET開発者が多くのコンピュートノードにまたがって並列実行するジョブ、一般に“驚異的並列”ワークロードと呼ばれるシチュエーションを簡単に記述できる点だ。
Microsoftは最近、HPC事業をServer and Cloud Groupに編入し、HPCをWindows Azureで実行することに注力している。Service Pack 1をインストールすれば、ユーザーはコンピュートノードをWindows Azure仮想マシン(VM)として実行することが可能になる。最も一般的なコンフィギュレーションは、「バーストシナリオ」と呼ばれるハイブリッドクラウドモードだ。このモードは、ヘッドノードがオンプレミスのデータセンターに置かれ、Windows Azureドライブにストアされたファイルセットとともに、負荷に応じて一連のコンピュートノードをWindows Azure VMとして実行するものだ。LINQ to HPCでは、Windows HPC Server上でLINQプログラミングモデルのデータ集約型コンピューティングを実行できる。
“Daytona”とExcel DataScopeは開発をシンプルにするか?
MSRがCloud Research Engagement Initiativeの一環としてコンピューティングの境界を広げるために設立したeXtreme Computing Group(XCG)は、2011年7月、“Daytona”プラットフォームをCommunity Technical Preview(CTP)としてリリースした。同グループは、同月後半にプロジェクトを再構築した。
DaytonaはWindows AzureのMapReduceランタイムで、Amazon Web Services(AWS)のElastic Map ReduceやApache FoundationのHadoop Map Reduce、MapRのApache Hadoopディストリビューション、Cloudera Enterprise Hadoopなどと競合する。“Daytona”の大きな優位性の1つは、Windows Azureに対して導入が容易な点だ。CTPは、プレビルトの.NET MapReduceライブラリおよびホストソースコード、k-meansクラスタリングおよび異常値検出分析用のC#コードとサンプルデータ、そして完全なドキュメントとともに基本導入パッケージを含む。
「Daytonaはマシンラーニングやデータ分析アルゴリズムを記述する開発者にとって、非常にシンプルで使い勝手の良いプログラミングインタフェースだ」と語るのは、XCGのCloud Computing Futures(CCF)チームを率いるアーキテクト、ロジャー・バルガ氏だ。「(開発者たちは)分散コンピューティングやコンピューテーションの分散化の仕組みについてあまり多く知る必要はなく、Windows Azureの詳細についても知る必要がない」
バルが氏は電話インタビューで、Daytona CTPは8週間という短期サイクルでアップデートされると述べた。こうしたインターバルにより、2010年のプレビュー後期ステージにおいて、Windows Azure CTPのアップデートスケジュールは並列化されている。次期Daytona CTPアップデートでは、RESTful APIの追加とパフォーマンスの改善が行われる。また2011年秋には、従来のバッチ処理機能にストリーム処理を追加できるMapReduceエンジンへのアップグレードが行われる予定だ。バルガ氏はさらに、オープンソースコミュニティーが同プロジェクトへの貢献に興味を示せば、オープンソース“Daytona”のリリースも検討していることを明らかにした。
オープンソース関連記事
MSRは2011年6月、最新のビッグデータ分析およびビジュアル化ツールのExcel DataScopeをリリースした。Excel DataScopeを利用すれば、ユーザーはリサーチリボンと呼ばれる使い慣れたスプレッドシートユーザーインタフェースを使って、データのアップロード、クラウドにストアされたデータからのパターン抽出、隠された関連性の特定、データセット間の類似性の発見、時系列予測の実行などが可能だ(図2)。

「Excelは、ユーザーのマシン上のリソースのみにアクセスできるクローズドなワールドビューを提供する。リサーチャーは、さまざまなモデルを利用するプログラマの一団のようなものだ。彼らはクラウドの中のデータを操作し、共有できる」とバルが氏は説明する。
「Excel DataScopeはAzure BLOBにストアされたワークスペースにデータをアップロードしたり、ダウンロードしたりするために、Windows Azureがオープンしたセッションを維持する。ワークスペースは、データや分析アルゴリズムへのアクセスを共有するためのプライベートなサンドボックスだ。ユーザーはジョブをキューに置くことができ、Excelを切断した後に再び復帰し、元の状態に戻ることができる。プログレスバーが分析のステータスを追尾している」。Silverlight PivotViewerがExcel DataScopeのデータビジュアル化機能を提供する。バルガ氏によると、2011年秋にも最初のExcel DataScope CTPが投入される見込みだ。
関連ホワイトペーパー
HPC | Microsoft(マイクロソフト) | Excel | データウェアハウス | クラウドコンピューティング | Google(グーグル) | データベース | データセンター | 検索エンジン | オンデマンド | オープンソース | ストレージ
Copyright © ITmedia, Inc. All Rights Reserved.