「De-duplication」や「重複除外」といった機能をうたったバックアップ製品が増えてきた。これは具体的にはどういう機能で、どのようなメリットがあるものなのだろうか?
通常、データをバックアップする際には元のデータ量よりかなり多くのストレージ容量が必要になる。例えば、フルバックアップを4週間分残すような運用をしている場合、単純に考えて元のデータ量の5倍以上のバックアップストレージ容量が必要になる。加えて、災害対策用に遠隔地にデータを保管する場合には、これがさらに増えることになる。
このように、ただでさえバックアップデータの容量は膨れ上がっているにもかかわらず、企業内には通常、同じようなデータが多数保存されている。例えば、ある商品紹介資料を、顧客名の部分だけを変更して幾つもファイルサーバに保存しているようなケースだ。バックアップ対象にこのようなデータが存在する場合、同じ内容を繰り返しバックアップすることになる。これはよく考えてみれば無駄なことをしているわけで、何とかこの無駄を取り除けないかと考えられたのが、“Data De-duplication”(以下、De-duplication)技術である。
“duplication”とは「重複」を意味する英単語だ。従って、“De-duplication”をそのまま日本語に訳すと「重複の除外」あるいは「重複の排除」とでもなろうか。文字通り、重複するデータを除外することによって、バックアップデータの容量を縮小する技術だ。
この技術はまだ新しいこともあり、業界的に統一した呼称がまだ存在しない。「De-duplication」(ディデュプリケーション)「De-dupe」(ディデュープ)「重複排除」「重複除外」「非重複化」などさまざまな呼び方をされているが、本稿では元の英語表記“De-duplication”をそのまま使うことにする。
同じデータのバックアップを省くことによって無駄を取り除くという方法は、以前から存在していた。De-duplication技術を理解しやすくするために、まずはその変遷を簡単に追ってみよう。
まず、かなり以前から存在しており、現在でも一般的に使われている「データ圧縮」も、考え方によってはDe-duplicationの一種といえる。なじみの深いところでは、テープバックアップの際に使われる圧縮がそれだ。一口に圧縮といっても幾つかの手法があるが、典型的なものでは1つのファイルの中にある「繰り返されているデータパターン」をポインタ(同じデータパターンの位置を指し示す値)に変換することで重複部分を省いている(図1)。
追って登場したのが、「ファイル単位でのDe-duplication」(ファイルレベルDe-duplication)の手法である。これは、アーカイブ用ストレージなどで使われる技術で、「シングルインスタンス機能」と呼ばれることも多い。
まずは、ファイルごとにユニークなアドレス(ファイルの位置を表す値)を割り当てる。そしてファイルを保存する際には、既に同じアドレスがないかを確認し、存在する場合はそのファイルのデータを保存しない(図2)。この方法により、同一ファイルを重複して保存することを避けられるわけだ。
ただし、この方法はファイル単位の処理なので、ファイルの内容がほんの少し異なるだけでも別のアドレスが割り当てられ、保存対象となる。
そして最近のDe-duplication技術としては、サブファイル単位で重複を省くタイプが徐々に市場に出回ってきた。この技術は米国では2003年ごろから登場しているが、日本で浸透し始めたのは2006年ごろからのことである。
これはファイルレベルDe-duplicationの考え方をさらに推し進めた方式で、1つのファイルをさらに細かく分割して、より細分化された単位で同一のデータを省くことができる(図3)。前述の例のような、顧客名の部分だけが異なる大量の商品資料ファイルを作成するようなケースであれば、顧客名以外の共通部分のデータは1つだけ保存されることになるため、大半のデータを削減することが可能だ。
なお、このサブファイル単位でのDe-duplicationは、米Data Domainの製品を代表とする、バックアップ用ディスクストレージにDe-duplication機能を組み込んだタイプのものと、「EMC Avamar」などのようにソフトウェアとして提供されている製品の2種類がある。最近はIBMやヒューレット・パッカード、国内の各ストレージメーカーなどがこぞってDe-duplication機能を備えたディスクストレージ製品を発表しており、市場が急速に活性化してきている。
Copyright © ITmedia, Inc. All Rights Reserved.

瞬時にM365が乗っ取られる――全社員に周知すべき“新フィッシング”の教訓
MFA(多要素認証)を入れたから安心という常識が崩れ去っている。フィッシング集団「Tycoon2FA」が摘発されたが、脅威が完全になくなったというわけではない。

「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。

「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。

「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...
![]()
ITmediaはアイティメディア株式会社の登録商標です。
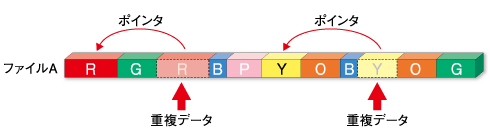 図1 データ圧縮
図1 データ圧縮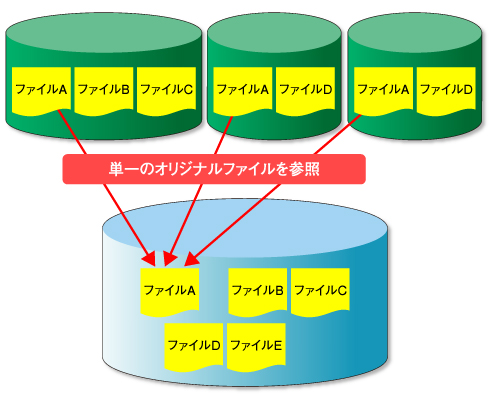 図2 シングルインスタンス機能
図2 シングルインスタンス機能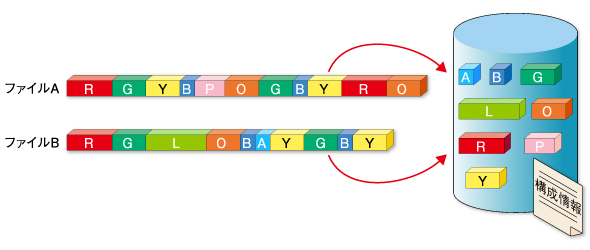 図3 サブファイルレベルDe-duplication
図3 サブファイルレベルDe-duplication



