加速度的に増加するデータ。放置しておけば、バックアップの処理時間も長くなる一方だ。しかしスナップショットとレプリケーションをうまく使えば、稼働系サーバに負荷を掛けずにバックアップを行うことができる。
24時間動き続けなければならないサーバでは、できるだけデータバックアップに時間を費やしたくないだろう。また、たとえ土日に作業をスケジューリングしていたとしても、バックアップ処理に時間がかかり過ぎて月曜日の始業時間になってもバックアップが終わらず、業務に支障が出てしまうというケースも間々見受けられる。そんな状態になるまで肥大化してしまったデータを、どうすればサーバに負荷を掛けずにバックアップすることができるだろうか?
時々、HDDストレージは単なるHDDの集まりだと思い込んでいる方がいるが、サーバと同様にCPUやメモリを持っていて、データ入出力の処理を行っている。もちろん、そのためのOSだって搭載されているのだ。さらに、ストレージ自体でデータを安全に守る仕組みを持っているものもある。こうしたストレージはバックアップ処理をストレージ側で行うため、稼働系サーバへの負担を軽くしてくれる。
冒頭で挙げたような、サーバになるべく負担を掛けずにバックアップを取りたいケースでは、なるべくストレージ側で処理を行う方がいいに決まっている。今回はそのような、ストレージ側で運用できるデータ保護の代表的な手法である「スナップショット」と「レプリケーション」について分かりやすく解説してみたいと思う。それぞれ特性があり、うまく組み合わせることで絶大な効果を挙げることができる。
まずスナップショットであるが、これは写真でいう「スナップショット」と同じように「その瞬間を切り取る」ことをいう。もちろん、切り取る対象は風景や人物ではなくデータなのだが、その瞬間を取っておくのに「データ自体」をコピーするのではなく、「ポインタ」と呼ばれる、データがどこにあるかという情報を記録するのが特徴だ。Windowsでいえば、ショートカットのようなものである。ポインタ自体のデータ量はごくわずかなので、ほんの数秒でどのデータがどの場所にあるかという情報を取ることができる。
スナップショットの最も優れた点は、ポインタ情報を使うことにより、スナップショットが作成したデータ領域を、元のデータ領域とまったく同じ内容の別データ領域として見せかけることができるところにある。別のサーバからスナップショットのデータ領域にアクセスすると、そのサーバのローカルディスクとして認識される。また、Windowsであればネットワークドライブとして使用することができる。
そのため、上図のように稼働系サーバとは別にバックアップ専用サーバを用意して、スナップショットのデータ領域をマウントすれば、このサーバ上だけでバックアップ作業を行うことができる(図1)。こうすれば、稼働系サーバ自体ではバックアップ作業を行う必要がなくなる。これで、稼働系サーバのバックアップ作業に掛かる負荷や時間をほとんど気にする必要がなくなるのだ。
Copyright © ITmedia, Inc. All Rights Reserved.

瞬時にM365が乗っ取られる――全社員に周知すべき“新フィッシング”の教訓
MFA(多要素認証)を入れたから安心という常識が崩れ去っている。フィッシング集団「Tycoon2FA」が摘発されたが、脅威が完全になくなったというわけではない。

「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。

「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。

「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...
![]()
ITmediaはアイティメディア株式会社の登録商標です。
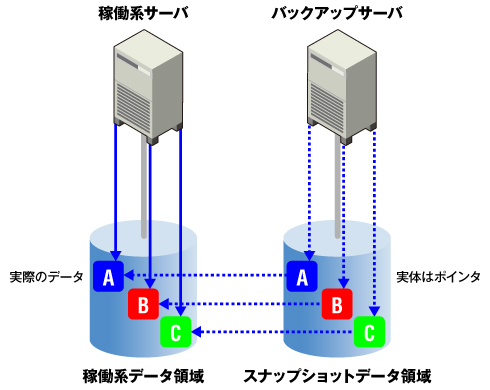 図1 スナップショット
図1 スナップショット



