レガシーな部品表があくまでも部品情報のためのデータベースだったのに対して、統合化部品表は部品のみならず、工程データや物流データなどさまざまな情報を取り込み、統合している。
前回「製造業の基幹データベースへと進化を遂げた部品表」では、レガシーホスト上に構築された原初の部品表が、時間軸や仕向地・生産地といった情報の新たな切り口を備えることにより、統合化部品表という新たな情報インフラとして生まれ変わった経緯を解説した。
現在の統合化部品表はそこからさらに発達し、製造業の統合情報インフラとなるべくさまざまな機能を備えている。今回はそれらを1つ1つ紹介していきたいと思う。
なお、今回紹介する機能は、統合化部品表の発展段階でいうと第3世代と第4世代で新たに導入されたものである。各世代の特徴については、本連載の第1回「製造業のバイブル『部品表(BOM)』の復権」を参照されたい。
エリヤフ・ゴールドラット(※1)は1991年の著書『The Haystack Syndrome』(邦題『ゴールドラット博士のコストに縛られるな!』)の中で、「BOMとRouting(工程データ、需給ルートデータ、物流ルートデータ)は、コンピュータの草創期にメモリやHDDなどの資源的な制約があって別々のデータベースとして発達し、現在でも分離されたままになっている。これはいずれ統合化されなければならない」と予言している。
※1 小説『The Goal』の著者で、TOC(Theory of Constraints:制約理論)の提唱者。
ゴールドラットが書いたように、部品表(BOM)と工程データは統合される必要がある。なぜなら、MRP(Material Requirements Planning:資材所要量計画)がMRP IからMRP IIへ進化するための条件であるCRP(Capacity Requirements Planning:能力所要量計画)を行うのに必要だからである。
もう少し詳しく説明しよう。MRP Iはオーダー(製造指示、発注指示、出庫指示などの具体的な生産活動を行う指示)を生成するのにリードタイムを使用する。リードタイムとは、発注リードタイム、製造リードタイムなどのように、部品や製品を発注してから納品されるまでの総時間のことである。MRP Iという生産管理システムは、あらかじめこのリードタイムを品目ごとに設定しておき、生産計画日を起点にしてオーダーを生成する仕組みなのである。
それに対してMRP IIというのは、そのオーダー生成の際にリードタイムだけでなく、さらに生産工程と生産能力も加味したものである。MRPで立案された計画オーダーをCRPで工程順に展開し、各工程の着手日と完了日の日程計算を行い、その結果を部門ごと(あるいはライン、ワークセンター、作業場所ごと)に積算して負荷積みをする。この計算を行う際に、工程手順や需給ルートなどの工程データが必要なのである。
さらに、各部門ごとに積んだ負荷のオーバー分を、実現可能な計画になるようスケジューラで一定の条件の下に山崩し(※2)し、再編成するのがAPS(Advanced Planning and Scheduling)である。ここでも、工程データは必須となる。
※2 各部門に割り当てられた作業負荷を、それぞれの負荷能力に合わせて平準化すること。
このような理由から、第3世代の統合化部品表には工程手順や需給ルートのデータが含まれるようになったのである。
Copyright © ITmedia, Inc. All Rights Reserved.

瞬時にM365が乗っ取られる――全社員に周知すべき“新フィッシング”の教訓
MFA(多要素認証)を入れたから安心という常識が崩れ去っている。フィッシング集団「Tycoon2FA」が摘発されたが、脅威が完全になくなったというわけではない。

「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。

「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。

「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...
![]()
ITmediaはアイティメディア株式会社の登録商標です。
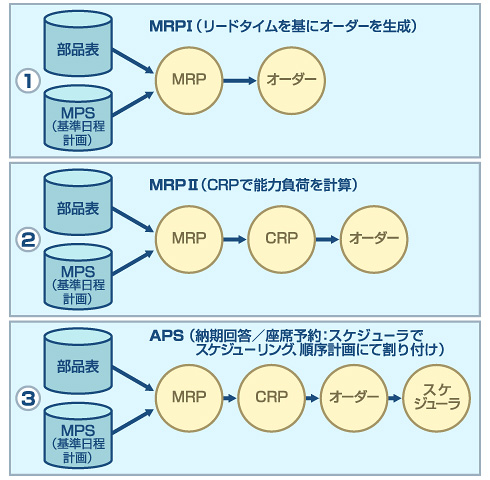 図1 MRP I、MRP II、APSの発展経緯
図1 MRP I、MRP II、APSの発展経緯



