顧客マスターにおける住所のクレンジング処理に強みを持つデータクレンジング/名寄せ製品が、富士通の「Interstage Information Quality」だ。その特徴を紹介する。
富士通の「Interstage Information Quality(IIQ)」は、顧客マスターに含まれる住所のクレンジング精度を高めつつ、高速処理を実現したデータクレンジング/名寄せ製品だ。必要最小限の機能を備え、200万円台から導入可能という手軽さも兼ね備える。IIQの特徴について、富士通に話を聞いた。
IIQは、顧客マスターに含まれる住所や氏名/法人名などを事前に指定したポリシーに従ってクレンジングし、名寄せまで実現する。処理結果はCSVファイルとして出力する(図1)。
クレンジング/名寄せ処理のコマンドを入力する画面はテキストベース(CUI)であり、GUIはクレンジング/名寄せのポリシー設定用画面だけである(画面1)。
パッケージソフトウェアや手組みのアプリケーションに、クレンジング機能をアドオンとして導入するためのAPIも用意する。アプリケーションの顧客情報入力フォームにクレンジング機能を埋め込むことで、エンドユーザーがシステムに入力したデータを即座に解析し、正しいデータの候補を表示したりできる(図2)。
データ品質を高めるためには、既存のデータだけでなく、当然ながら新しく発生するデータのクレンジングも同時に進める必要がある。APIを使って入力時にデータの誤りや過不足を発見することができれば、入力後のデータをあらためてクレンジングする手間を省くことができる。
現時点では、APIを利用しているユーザー企業は少数だと富士通は明かす。ただし、コンシューマー向けのWebサイトなど大量のデータが入力されるケースでは、APIを活用するメリットは大きい。
IIQは、クレンジング/名寄せの精度と速度向上に工夫を凝らす。特に注目すべきは、住所のクレンジング処理に利用するアルゴリズムの工夫だ。
Copyright © ITmedia, Inc. All Rights Reserved.

瞬時にM365が乗っ取られる――全社員に周知すべき“新フィッシング”の教訓
MFA(多要素認証)を入れたから安心という常識が崩れ去っている。フィッシング集団「Tycoon2FA」が摘発されたが、脅威が完全になくなったというわけではない。

「サイト内検索」&「ライブチャット」売れ筋TOP5(2025年5月)
今週は、サイト内検索ツールとライブチャットの国内売れ筋TOP5をそれぞれ紹介します。

「ECプラットフォーム」売れ筋TOP10(2025年5月)
今週は、ECプラットフォーム製品(ECサイト構築ツール)の国内売れ筋TOP10を紹介します。

「パーソナライゼーション」&「A/Bテスト」ツール売れ筋TOP5(2025年5月)
今週は、パーソナライゼーション製品と「A/Bテスト」ツールの国内売れ筋各TOP5を紹介し...
![]()
ITmediaはアイティメディア株式会社の登録商標です。
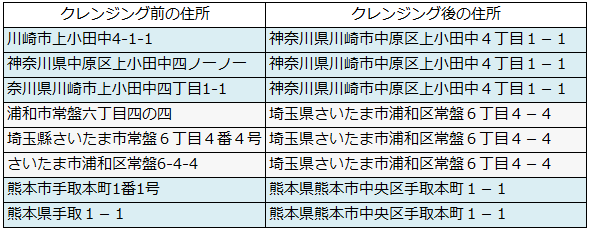 図1:IIQのクレンジング結果の例。結果はCSVファイルとして出力される
図1:IIQのクレンジング結果の例。結果はCSVファイルとして出力される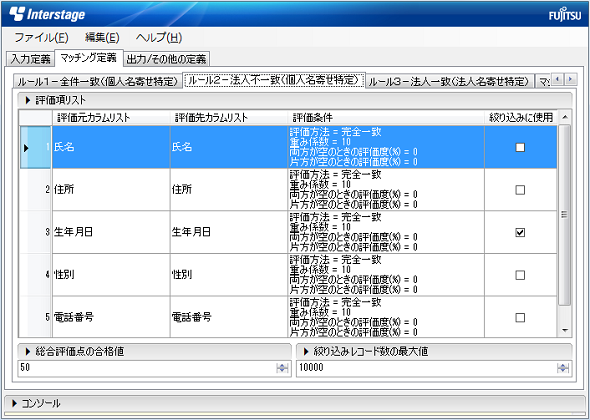 画面1:IIQは、GUIのクレンジング/名寄せポリシー設定画面を用意する(画面は名寄せポリシーの設定画面)
画面1:IIQは、GUIのクレンジング/名寄せポリシー設定画面を用意する(画面は名寄せポリシーの設定画面)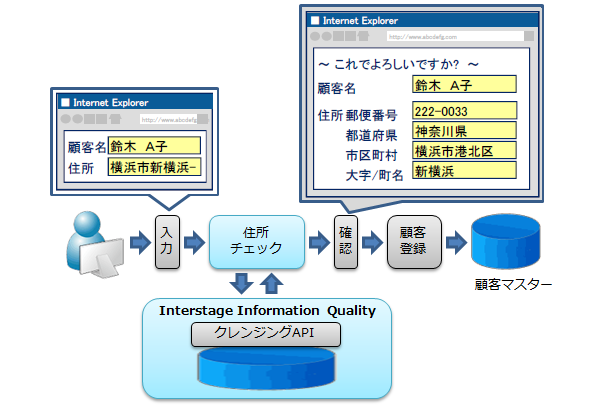 図2:APIを利用したクレンジングの例。アプリケーションのエンドユーザーが入力したデータを基に、修正候補の確認画面を表示する(出典:富士通の製品紹介資料を基に作成)
図2:APIを利用したクレンジングの例。アプリケーションのエンドユーザーが入力したデータを基に、修正候補の確認画面を表示する(出典:富士通の製品紹介資料を基に作成)



