ビッグデータは、大量かつ多様なデータと、そのデータを高速で収集、処理、分析するための技術を指す。ビッグデータには構造化データと半構造化データ、非構造化データが含まれ、これらは機械学習や予測モデル、その他の高度なデータ分析アプリケーションで使用される。

AWSはIT人材を育成するための幾つかの施策に取り組んでいる。同社が奨学金制度や、女子生徒向けの教育プログラムを提供する狙いとは。

連続的に発生し続けるデータを処理するミドルウェア「Kafka」のユーザー企業には、PorscheやSony Interactive Entertainmentといった著名企業もある。彼らはKafkaをどう活用し、競争力の向上を図っているのか。

BMWは、連続的に発生し続けるデータを処理するミドルウェア「Kafka」を自動車製造に役立てているという。どのように活用しているのか。同社責任者の話を基にコンパクトに紹介する。

Walmartは「Apache Kafka」を利用して、自社サービスのオンライン取引の不正検出を実行するシステムを開発した。同社はある課題を解決するために、Kafkaプロジェクトへの貢献を惜しまなかったという。その課題とは。

ガートナーのイベントにおけるメルカリの松田 慎太郎氏の基調講演から、同社における分析の組織と文化の作り方についてまとめた。製品選定の話ではないが、分析を社内に根付かせる上で参考になるはずだ。

ヤフーが新しいデータ分析サービスを発表した。「Yahoo!ショッピング」や「Yahoo!ニュース」「Yahoo!検索」など、同社サービスのユーザーの利用データを基に、消費者の関心を可視化できる。

複数のデータベースに異なる形で保存され、同じ人あるいは物を指しているのかどうかも分からない。このような状態から脱し、データをビジネスに活用するにはどうすればいいのか。

保険会社IAGが保有するデータは、1年間で80TBから2PBに増加した。この間に、データの量だけでなくストレージシステム、管理方法、クラウドなども大きく変化した。ストレージ戦略を見直すべき時がきたのだ。

かつて、顧客に酷評されたHANAの導入が増えている。特にアジア太平洋地域で伸びているという、HANAの現状を紹介する。

「Hadoop」の生みの親の1人であるカッティング氏に、現在の活動、Hadoopの今後、サイバーセキュリティとビッグデータの関係について聞いた。

HPEが開発中の次世代アーキテクチャであるメモリ主導型コンピューティングはコンピュータの歴史を塗り替えるのか。同社のCTOに、現在進行している「The Machine」の応用と展開について聞いた

ゲーム関連企業のGAME Digitalは、徹底した顧客データ収集と活用によって、さまざまな経営指標を向上させている。しかし、「われわれは特別なソフトウェアを使っているわけではない」という。

Bloombergでデータサイエンス(自然言語処理、情報の検索と取得、機械学習)を引きているギデオン・マン氏。2008年から機械学習を手掛けてきた同氏には、機械学習の可能性とともに課題も見えている。

自社開発したデータ視覚化ツールのオープンソース化に踏み切ったUber Technologies。その狙いは、イノベーションを自社に環流させることにある。

HPが2014年6月の発表から3年弱、同社が「メモリドリブンコンピューティング」と呼ぶ「The Machine」はどうなっているのか? HPE首席アーキテクトにノイマン型の限界とThe Machineが目指すものを聞いた。

次世代のスポーツ会場では、チームの本拠地スタジアムのネットワークが戦略的リソースの役割を果たし、ファンの関わりを促して収益を押し上げる。
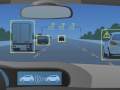
BMW GroupとIBMが、自動車の操作にWatsonを応用する研究を行っている。自動車にWatsonが組み込まれることにより、何が実現するのだろうか。

Microsoftのキャメロン氏は、「場当たり的な施策の寄せ集め」である現在のIDインフラの刷新を主張する。彼が酷評する現在の技術の何が問題なのか。どう変えればいいというのか。

複数のHadoopディストリビューターからどの製品を選ぶべきなのか。ドイツの再保険会社は、製品以外の面に注目することで導入を成功させた。彼らの製品選定を決定付けた要因とは何か?
企業はビッグデータをシステムに組み込むことで、業務効率を向上させたり、より良い顧客サービスを提供したり、顧客一人一人にパーソナライズした販促キャンペーンを実行したりできる。
ビッグデータを効果的に利用する企業は、事業判断のスピードと正確性を向上させて、競争力を高められる可能性がある。例えばビッグデータは、顧客に関する貴重な洞察を提供する。こうした洞察は企業のマーケティング活動を洗練させて、顧客の満足度を向上させるために利用できる。過去のデータとリアルタイムのデータの両方を分析することで、消費者や顧客企業の需要の変化を評価して、すぐにその需要に合わせられるようになる。
医師は疾患の兆候とリスクを特定したり、診断を補助したりするためにビッグデータを利用できる。感染症対策にも有用だ。医療機関や電子健康記録やソーシャルメディア、Webサイト、その他の情報源からのデータを収集して組み合わせて分析することで、感染症の発生状況や患者者数の予測ができる。
他にもさまざまな業界でビッグデータが使われている。
ビッグデータは、取引処理システムや顧客データベース、電子メール、医療記録、インターネットのクリックログ、モバイルアプリケーション、ソーシャルネットワークなど、さまざまなデータ源から生じる。テキスト形式のデータに加えて画像や動画、オーディオファイルもまた、ビッグデータの形態だ。
ネットワークやサーバのログファイル、製造機械、IoT(モノとインターネット)デバイスからのセンサーデータなど、機械が生成するデータもビッグデータに含まれる。組織の業務システムが取得したデータに加えて、金融市場や気象、交通状況などに関する統計データや地理情報、科学研究など、組織外から取得したデータをビッグデータとして扱うこともある。
ビッグデータを表す3つのVという概念がある。3つのVは、それぞれ以下の意味を持つ。
3つのVは2001年に調査会社META Groupのアナリストだったダグ・ラニー氏が提唱した。最近ではデータの正しさ(Veracity)や価値(Value)、変動性(Variability)など、他のVを追加して、ビッグデータについて説明することもある。これらのVには以下の意味合いがある。
![]()
ITmediaはアイティメディア株式会社の登録商標です。
